How Rendering Work (in WebKit and Blink)
How Rendering Work (in WebKit and Blink)
自从开始从事浏览器内核开发工作以来,已经写过不少跟渲染相关的文章。但是一直想写一篇像 How Browsers Work 类似,能够系统,完整地阐述浏览器的渲染引擎是如何工作的,它是如何对网页渲染性能进行优化的文章,却一直因为畏惧所需要花费的时间和精力,迟迟无法动笔。不管如何,现在终于鼓起勇气来写了,希望自己能够完成吧…
文章包括的主要内容如下 —
- 渲染基础 - DOM & RenderObject & RenderLayer
- WebView,绘制与混合,多线程渲染
- 硬件加速
- 分块渲染
- 图层混合加速
- 网页游戏渲染 - Canvas & WebGL
首先明确文中关于渲染的定义,浏览器内核引擎通常又被称为网页渲染引擎,但是这里的渲染实际上是一个泛指,广义的渲染,它包括了浏览器内核所有的主要工作 - 加载,解析,排版,绘制等等。而在本文里面的渲染,指的是跟绘制相关的部分,也就是浏览器是如何将排版后的结果最终显示在屏幕上的这一过程。如果读者希望先对浏览器内核引擎,特别是 WebKit 有一个大概的了解,How Browsers Work,How WebKit Work,WebKit for Developers 可以提供不错的入门指引。
其次,本文主要描述 WebKit 引擎的实现,不过因为 Blink 实际上从 WebKit 分支出来的时间并不长,两者在渲染整体架构上还是基本一致的,所以文中不会明确区分这两者。
最后,希望这篇文章能够给从事浏览器内核开发,特别是渲染引擎开发的开发者一个能够快速入门的指引,并给前端开发者优化网页渲染性能提供足够的知识和帮助。
因为文章后续还有可能会持续修订和补充,如果要查看最新的内容,请访问个人博客的原文:http://blog.csdn.net/rogeryi/article/details/23686609,如果有什么疏漏和错误,也欢迎读者来信指正(roger2yi@gmail.com)。
渲染基础 - DOM & RenderObject & RenderLayer

当浏览器通过网络或者本地文件系统加载一个 HTML 文件,并对它进行解析完毕后,内核就会生成它最重要的数据结构 - DOM 树。DOM 树上每一个节点都对应着网页里面的每一个元素,并且网页也可以通过 JavaScript 操作这棵 DOM 树,动态改变它的结构。但是 DOM 树本身并不能直接用于排版和渲染,内核还会生成另外一棵树 - Render 树,Render 树上的每一个节点 - RenderObject,跟 DOM 树上的节点几乎是一一对应的,当一个可见的 DOM 节点被添加到 DOM 树上时,内核就会为它生成对应的 RenderOject 添加到 Render 树上。

图片来自 How WebKit Work
Render 树是浏览器排版引擎的主要作业对象,排版引擎根据 DOM 树和 CSS 样式表的样式定义,按照预定的排版规则确定了 Render 树最后的结构,包括其中每一个 RenderObject 的大小和位置,而一棵经过排版的 Render 树,则是浏览器渲染引擎的主要输入,读者可以认为,Render 树是衔接浏览器排版引擎和渲染引擎之间的桥梁,它是排版引擎的输出,渲染引擎的输入。

图片来自 How WebKit Work
不过浏览器渲染引擎并不是直接使用 Render 树进行绘制,为了方便处理 Positioning(定位),Clipping(裁剪),Overflow-scroll(页內滚动),CSS Transform/Opacity/Animation/Filter,Mask or Reflection,Z-indexing(Z排序)等,浏览器需要生成另外一棵树 – Layer 树。渲染引擎会为一些特定的 RenderObject 生成对应的 RenderLayer,而这些特定的 RenderObject 跟对应的 RenderLayer 就是直属的关系,相应的,它们的子节点如果没有对应的 RenderLayer,就从属于父节点的 RenderLayer。最终,每一个 RenderObject 都会直接或者间接地从属于一个 RenderLayer。
RenderObject 生成 RenderLayer 的条件,来自 GPU Accelerated Compositing in Chrome
- It’s the root object for the page
- It has explicit CSS position properties (relative, absolute or a transform)
- It is transparent
- Has overflow, an alpha mask or reflection
- Has a CSS filter
- Corresponds to canvas element that has a 3D (WebGL) context or an accelerated 2D context
- Corresponds to a video element
浏览器渲染引擎遍历 Layer 树,访问每一个 RenderLayer,再遍历从属于这个 RenderLayer 的 RenderObject,将每一个 RenderObject 绘制出来。读者可以认为,Layer 树决定了网页绘制的层次顺序,而从属于 RenderLayer 的 RenderObject 决定了这个 Layer 的内容,所有的 RenderLayer 和 RenderObject 一起就决定了网页在屏幕上最终呈现出来的内容。
软件渲染模式下,浏览器绘制 RenderLayer 和 RenderObject 的顺序,来自 GPU Accelerated Compositing in Chrome
In the software path, the page is rendered by sequentially painting all the RenderLayers, from back to front. The RenderLayer hierarchy is traversed recursively starting from the root and the bulk of the work is done in RenderLayer::paintLayer() which performs the following basic steps (the list of steps is simplified here for clarity):
- Determines whether the layer intersects the damage rect for an early out.
- Recursively paints the layers below this one by calling paintLayer() for the layers in the negZOrderList.
- Asks RenderObjects associated with this RenderLayer to paint themselves.
- This is done by recursing down the RenderObject tree starting with the RenderObject which created the layer. Traversal stops whenever a RenderObject associated with a different RenderLayer is found.
- Recursively paints the layers above this one by calling paintLayer() for the layers in the posZOrderList.
In this mode RenderObjects paint themselves into the destination bitmap by issuing draw calls into a single shared GraphicsContext (implemented in Chrome via Skia).
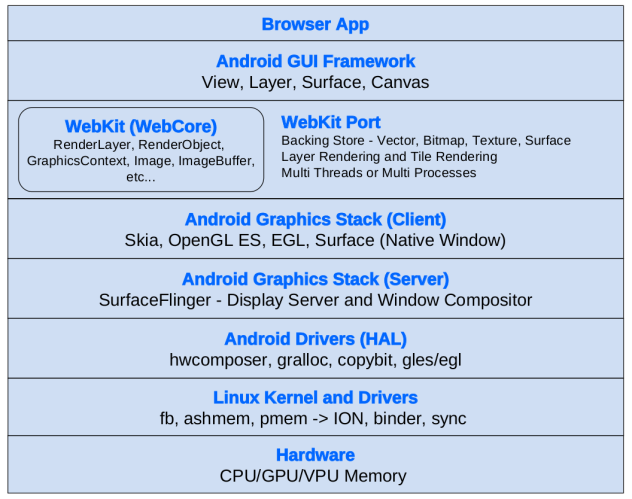
WebView,绘制与混合,多线程渲染

图片来自 [UC 浏览器 9.7 Android版],中间是一个 WebView,上方是标题栏和工具栏
浏览器本身并不能直接改变屏幕的像素输出,它需要通过系统本身的 GUI Toolkit。所以,一般来说浏览器会将一个要显示的网页包装成一个 UI 组件,通常叫做 WebView,然后通过将 WebView 放置于应用的 UI 界面上,从而将网页显示在屏幕上。
一些 GUI Toolkit,比如 Android,默认的情况下 UI 组件没有自己独立的位图缓存,构成 UI 界面的所有 UI 组件都直接绘制在当前的窗口缓存上,所以 WebView 每次绘制,就相当于将它在可见区域内的 RenderLayer/RenderObject 逐个绘制到窗口缓存上。上述的渲染方式有一个很严重的问题,用户拖动网页或者触发一个惯性滚动时,网页滑动的渲染性能会十分糟糕。这是因为即使网页只移动一个像素,整个 WebView 都需要重新绘制,而要绘制一个 WebView 大小的区域的 RenderLayer/RenderObject,耗时通常都比较长,对于一些复杂的桌面版网页,在移动设备上绘制一次的耗时有可能需要上百毫秒,而要达到60帧/每秒的流畅度,每一帧绘制的时间就不能超过16.7毫秒,所以在这种渲染模式下,要获得流畅的网页滑屏效果,显然是不可能的,而网页滑屏的流畅程度,又是用户对浏览器渲染性能的最直观和最重要的感受。
要提升网页滑屏的性能,一个简单的做法就是让 WebView 本身持有一块独立的缓存,而 WebView 的绘制就分成了两步 1) 根据需要更新内部缓存,将网页内容绘制到内部缓存里面 2) 将内部缓存拷贝到窗口缓存上。第一步我们通常称为绘制(Paint)或者光栅化(Rasterization),它将一些绘图指令转换成真正的像素颜色值,而第二步我们一般称为混合(Composite),它负责缓存的拷贝,同时还可能包括位移(Translation),缩放(Scale),旋转(Rotation),Alpha 混合等操作。咋一看,渲染变得比原来更复杂,还多了一步操作,但实际上,混合的耗时通常远远小于网页内容绘制的耗时,后者即使在移动设备上一般也就在几个毫秒以内,而大部分时候,在第一步里面,我们只需要绘制一块很小的区域而不需要绘制一个完整 WebView 大小的区域,这样就有效地减少了绘制这一步的开销。以网页滚动为例子,每次滚动实际上只需要绘制新进入 WebView 可见区域的部分,如果向上滚动了10个像素,我们需要绘制的区域大小就是10 x Width of WebView,比起原来需要绘制整个 WebView 大小区域的网页内容当然要快的多了。
进一步来说,浏览器还可以使用多线程的渲染架构,将网页内容绘制到缓存的操作放到另外一个独立的线程(绘制线程),而原来线程对 WebView 的绘制就只剩下缓存的拷贝(混合线程),绘制线程跟混合线程之间可以使用同步,部分同步,完全异步等作业模式,让浏览器可以在性能与效果之间根据需要进行选择,比如说异步模式下,当浏览器需要将 WebView 缓存拷贝到窗口缓存,但是需要更新的部分还没有来得及绘制时,浏览器可以在还未及时更新的部分绘制一个背景色或者空白,这样虽然渲染效果有所下降,但是保证了每一帧窗口更新的间隔都在理想的范围内。并且浏览器还可以为 WebView 创建一个更大的缓存,超过 WebView本身的大小,让我们可以缓存更多的网页内容,可以预先绘制不可见的区域,这样就可以有效减少异步模式下出现空白的状况,在性能和效果之间取得更好的平衡。
硬件加速
上述的渲染模式,无论是绘制还是混合,都是由 CPU 完成的,而没有使用到 GPU。绘制任务比较复杂,较难使用 GPU 来完成,并且对于各种复杂的图形/文本的绘制来说,使用 GPU 效率有时反而更低(并且系统资源的开销也较大),但是混合就不一样了,GPU 最擅长的就是并行处理多个像素的计算,所以 GPU 相对于 CPU,执行混合的速度要快的多,特别是存在缩放,旋转,Alpha 混合的时候,而且混合相对来说也比较简单,改成使用 GPU 来完成并不困难。
并且在多线程渲染模式下,因为绘制和混合分别处于不同的线程,绘制使用 CPU,混合使用 GPU,这样可以通过 CPU/GPU 之间的并发运行有效地提升浏览器整体的渲染性能。更何况,窗口的更新是由混合线程来负责的,混合的效率越高,窗口更新的间隔就越短,用户感受到 UI 界面变化的流畅度就越高,只要窗口更新的间隔能够始终保持在16.7毫秒以内,UI 界面就能够一直保持60帧/每秒的极致流畅度(因为一般来说,显示屏幕的刷新频率是60hz,所以60帧/秒已经是极限帧率,超过这个数值意义不大,而且 OS 的图形子系统本身就会强制限制 UI 界面的更新跟屏幕的刷新保持同步)。
所以对于现代浏览器来说,所谓硬件加速,就是使用 GPU 来进行混合,绘制仍然使用 CPU 来完成。
分块渲染

图片来自 [UC 浏览器 9.7 Android版],使用256×256大小的分块
网页的缓存通常都不是一大块,而是划分成一格一格的小块,通常为256×256或者512×512大小,这种渲染方式称为分块渲染(Tile Rendering)。使用分块渲染的主要原因是因为 –
- 所谓 GPU 混合,通常是使用 Open GL/ES 贴图来实现的,而这时的缓存其实就是纹理(GL Texture),而很多 GPU 对纹理的大小有限制,比如长/宽必须是2的幂次方,最大不能超过2048或者4096等,所以无法支持任意大小的缓存;
- 使用小块缓存,方便浏览器使用一个统一的缓存池来管理分配的缓存,这个缓存池一般会分配成百上千个缓存块供所有的 WebView 共用。所有打开的网页,需要缓存时都可以以缓存块为单位向缓存池申请,而当网页关闭或者不可见时,这些不需要的缓存块就可以被回收供其它网页使用;
总之固定大小的小块缓存,通过一个统一缓存池来管理的方式,比起每个 WebView 自己持有一大块缓存有很多优势。特别是更适合多线程 CPU/GPU 并发的渲染模型,所以基本上支持硬件加速的浏览器都会使用分块渲染的方式。
图层混合加速

图片来自 [UC 浏览器 9.7 Android版],可见区域内有4个 Layer 有自己的缓存 – 最底层的 Base Layer,上方的 Fixed 标题栏,中间的热点新闻栏,右下方的 Fixed 跳转按钮
图层混合加速(Accelerated Compositing)的渲染架构是 Apple 引入 WebKit 的,并在 Safari 上率先实现,而 Chrome/Android/Qt/GTK+ 等都陆续完成了自己的实现。如果熟悉 iOS 或者 Mac OS GUI 编程的读者对其应该不会感到陌生,它跟 iOS CoreAnimation 的 Layer Rendering 渲染架构基本类似,主要都是为了解决当 Layer 的内容频繁发生变化,或者当 Layer 触发一个2D/3D变换(2D/3D Transform )或者渐隐渐入动画,它的位移,缩放,旋转,透明度等属性不断发生变化时,在原有的渲染架构下,渲染性能低下的问题。
非混合加速的渲染架构,所有的 RenderLayer 都没有自己独立的缓存,它们都被绘制到同一个缓存里面(按照它们的先后顺序),所以只要这个 Layer 的内容发生变化,或者它的一些 CSS 样式属性比如 Transform/Opacity 发生变化,变化区域的缓存就需要重新生成,此时不但需要绘制变化的 Layer,跟变化区域(Damage Region)相交的其它 Layer 都需要被绘制,而前面已经说过,网页的绘制是十分耗时的。如果 Layer 偶尔发生变化,那还不要紧,但如果是一个 JavaScript 或者 CSS 动画在不断地驱使 Layer 发生变化,这个动画要达到60帧/每秒的流畅效果就基本不可能了。
而在混合加速的渲染架构下,一些 RenderLayer 会拥有自己独立的缓存,它们被称为混合图层(Compositing Layer),WebKit 会为这些 RenderLayer 创建对应的 GraphicsLayer,不同的浏览器需要提供自己的 GrphicsLayer 实现用于管理缓存的分配,释放,更新等等。拥有 GrphicsLayer 的 RenderLayer 会被绘制到自己的缓存里面,而没有 GrphicsLayer 的 RenderLayer 它们会向上追溯有 GrphicsLayer 的父/祖先 RenderLayer,直到 Root RenderLayer 为止,然后绘制在有 GrphicsLayer 的父/祖先 RenderLayer 的缓存上,而 Root RenderLayer 总是会创建一个 GrphicsLayer 并拥有自己独立的缓存。最终,GraphicsLayer 又构成了一棵与 RenderLayer 并行的树,而 RenderLayer 与 GraphicsLayer 的关系有些类似于 RenderObject 与 RenderLayer 之间的关系。
混合加速渲染架构下的网页混合,也变得比以前复杂,不再是简单的将一个缓存拷贝到窗口缓存上,而是需要完成源自不同 Layer 的多个缓存的拷贝,再加上可能的2D/3D变换,再加上缓存之间的Alpha混合等操作,当然,对于支持硬件加速,使用 GPU 来完成混合的浏览器来说,速度还是很快的。
RenderLayer 生成 GraphicsLayer 的条件,来自 GPU Accelerated Compositing in Chrome
- Layer has 3D or perspective transform CSS properties
- Layer is used by < video> element using accelerated video decoding
- Layer is used by a < canvas> element with a 3D context or accelerated 2D context
- Layer is used for a composited plugin
- Layer uses a CSS animation for its opacity or uses an animated webkit transform
- Layer uses accelerated CSS filters
- Layer with a composited descendant has information that needs to be in the composited layer tree, such as a clip or reflection
- Layer has a sibling with a lower z-index which has a compositing layer (in other words the layer is rendered on top of a composited layer)
混合加速的渲染架构下,Layer 的内容变化,只需要更新所属的 GraphicsLayer 的缓存即可,而缓存的更新,也只需要绘制直接或者间接属于这个 GraphicsLayer 的 RenderLayer 而不是所有的 RenderLayer。特别是一些特定的 CSS 样式属性的变化,实际上并不引起内容的变化,只需要改变一些 GraphicsLayer 的混合参数,然后重新混合即可,而混合相对绘制而言是很快的,这些特定的 CSS 样式属性我们一般称之为是被加速的,不同的浏览器支持的状况不太一样,但基本上CSS Transform & Opacity 在所有支持混合加速的浏览器上都是被加速的。被加速的CSS 样式属性的动画,就比较容易达到60帧/每秒的流畅效果了。

图片来自 Understanding Hardware Acceleration on Mobile Browsers,展现了经典的 CSS 动画 Demo – Falling Leaves 的图层混合的示意图,它所使用的 Transform 和 Opacity 动画在所有支持混合加速的浏览器上都是被加速的
不过并不是拥有独立缓存的 RenderLayer 越多越好,太多拥有独立缓存的 Layer 会带来一些严重的副作用 – 首先它大大增加了内存的开销,这点在移动设备上的影响更大,甚至导致浏览器在一些内存较少的移动设备上无法很好地支持图层混合加速;其次,它加大了混合的时间开销,导致混合性能的下降,而混合性能跟网页滚动/缩放操作的流畅度又息息相关,最终导致网页滚动/缩放的流畅度下降,让用户觉得操作不够流畅。
在 Chrome://flags 里面开启“合成渲染层边框”就可以看到哪些 Layer 是一个 Compositing Layer,也就是拥有自己的独立缓存。前端开发者可以用此帮助自己控制 Compositing Layer 的创建。总的的说, Compositing Layer 可以提升绘制性能,但是会降低混合性能,网页只有合理地使用 Compositing Layer,才能在绘制和混合之间取得一个良好的平衡,实现整体渲染性能的提升。

图片来自 Chrome,展现了经典的 CSS 动画 Demo – Falling Leaves 的合成渲染层边框
网页游戏渲染 - Canvas & WebGL

图片来自 [UC 浏览器 9.7 Android版],基于2D Canvas 的游戏不江湖,在主流配置手机上可以达到60帧/每秒的流畅度
以前网页游戏一般都是使用 Flash 来实现,但是随着 Flash 从移动设备被淘汰,越来越多的网页游戏会改用 Canvas 和 WebGL 来开发,浏览器关于 Canvas 的基本绘制流程可以参考我以前的文章Introduce My Work。虽然一般网页元素都是使用 CPU 来绘制,但是对于加速的2D Canvas 和 WebGL 来说,它们的绘制是直接使用 GPU 的,所以它们一般会拥有一个GL FBO(FrameBufferObject)作为自己的缓存,Canvas/WebGL 的内容被绘制到这个 FBO 上面,而这个 FBO 所关联的纹理再在混合操作里面被拷贝到窗口缓存上。简单的来说,对于加速的2D Canvas 和 WebGL,它们的绘制和混合都是使用 GPU。

图片来自 [UC 浏览器 9.7 Android版],一个演示 WebGL 的网页 Demo
关于如何优化 Canvas 游戏的性能,请参考我以前的文章 – High Performance Canvas Game for Android(高性能Android Canvas游戏开发)。
参考索引
How Browsers Work: Behind the scenes of modern web browsers
How WebKit Work
WebKit for Developers
GPU Accelerated Compositing in Chrome
Understanding Hardware Acceleration on Mobile Browsers
Web Page Rendering and Accelerated Compositing
我的2013 – 年终总结 + 浏览器渲染发展的一些思考
Introduce My Work
High Performance Canvas Game for Android(高性能Android Canvas游戏开发)
OpenGL Frame Buffer Object (FBO)




回复